人工智能
人工智能术语解释
人工智能AI工具合集
AI编程插件和IDE
WPS/Office安装AI插件
搭建本地知识库:ima.copilot和pandawiki
Windows使用LM Studio部署DeepSeek R1模型
python调用LM Studio(AI)本地API
AI人工智能第三方API大全
Windows安装CUDA环境
Windows使用LLaMA-Factory微调LlaMA 3大模型
Ubuntu虚拟机部署Dify+Ollama搭建智能体和工作流
通过MCP调用Kali工具
MCP介绍和服务导航
大模型安全相关资料
IDE中kali MCP不能显示和无法连接的问题
本文档使用 MrDoc 发布
-
+
首页
Windows使用LLaMA-Factory微调LlaMA 3大模型
# 说明 本文演示使用`LLaMA-Factory`在**计算机本地**对`Meta-Llama-3.1-8B-Instruct`模型(一共30G)进行**微调**。 - 显卡:建议24 GB以上显存尝试。演示用NVIDIA GeForce GTX 1650 Ti(笔记本中低端显卡) - 内存:建议电脑有32G以上运行内存(是内存不是硬盘空间)尝试。 - 硬盘:建议SSD 512G以上。 其他微调方法:在云端(利用免费资源)进行微调,例如:Colab / 硅基流动。 <font color="red">本文的主要作用是通过实验理解大模型微调过程以及相关配置,实际微调需要使用高配置服务器。</font> # 大模型微调的标准流程 ## 环境准备: - 安装必要的 Python 依赖库,如 PyTorch、TensorFlow 等。 - 确保硬件环境支持,如 GPU 或 TPU,以加速训练。 ## 数据准备: - 收集与目标任务相关的数据,数据应包含提示词(Prompt)和期望的输出。 - 数据预处理,如分词、编码等,将其转换为适合模型输入的格式。 - 选择基座模型:从 Hugging Face、ModelScope 等平台下载适合任务的预训练大模型。 ## 微调方法选择: - 根据资源和任务需求选择合适的微调方法,如全量参数更新(FFT)、参数高效微调(PEFT)等。 - 常见的微调方法还包括 LoRA、QLoRA、Prompt Tuning 等。 ## 微调过程: - 加载预训练模型和分词器。 - 应用所选的微调方法,如配置 LoRA 参数。 - 设置超参数,如学习率、批量大小等。 - 启动微调训练,并通过可视化工具(如 SwanLab)监控训练过程。 ## 模型评估与优化: - 使用测试数据集对微调后的模型进行评估。 - 根据评估结果调整超参数或微调方法,进一步优化模型。 ## 模型保存与部署: - 保存微调后的模型权重。 - 将模型部署到实际应用中,如通过 Web API 提供服务 # <font color="red">前提条件(必做)</font> B21-Windows安装python3.x https://wiki.bafangwy.com/doc/604/ Windows安装CUDA环境(包含了支持gpu的pytorch) https://wiki.bafangwy.com/doc/813/ 安装git(用于下载模型) https://wiki.bafangwy.com/doc/812/ # 下载LLaMA-Factory LLaMA-Factory是一个开源的大规模语言模型微调框架,旨在简化大模型的训练过程,提供多种预训练模型和微调算法的支持。 https://github.com/hiyouga/LLaMA-Factory 点 Code —— Download 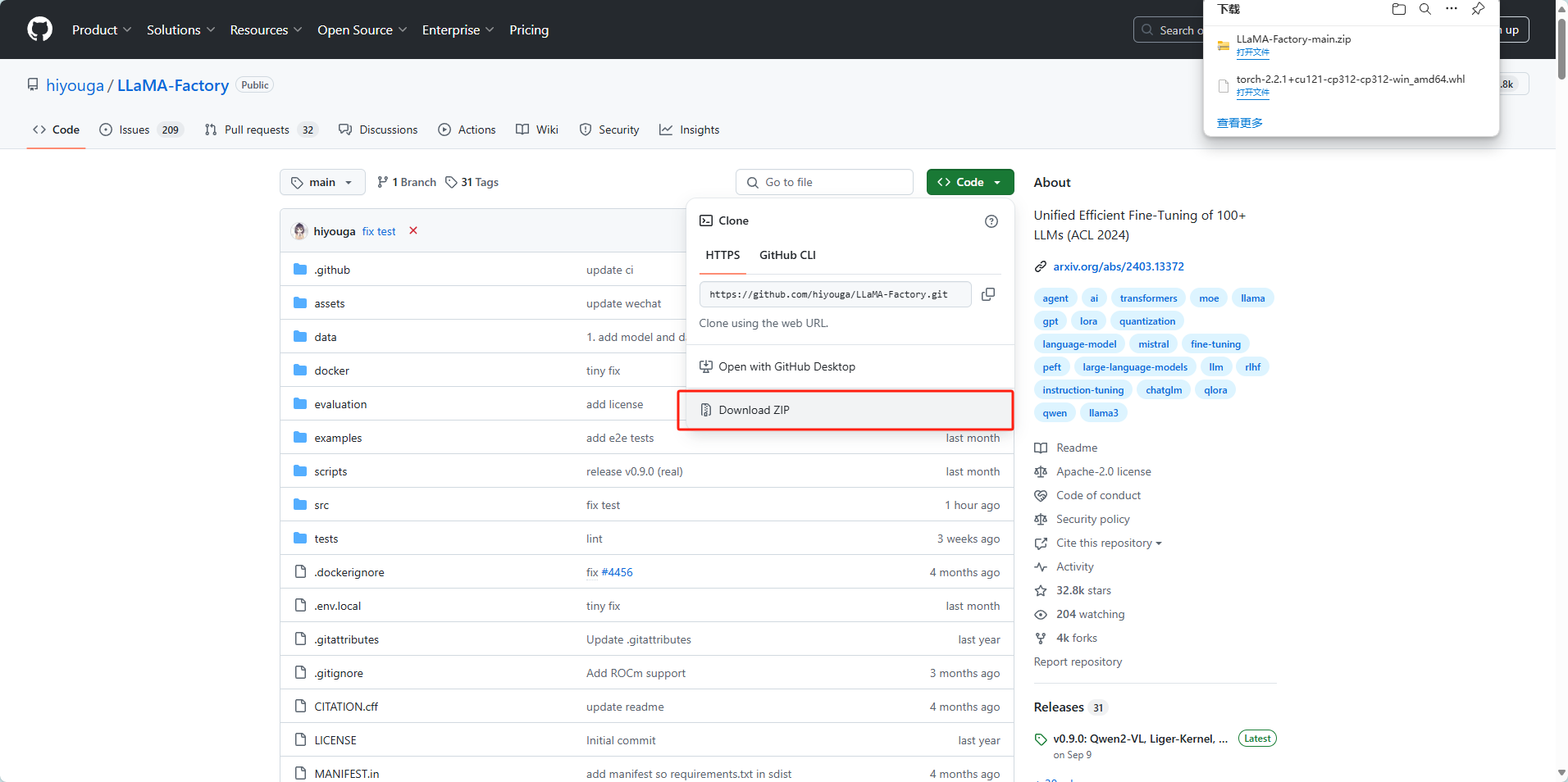 在LLaMA-Factory根目录下 比如:`D:\dev_python\LLaMA-Factory-main` 打开cmd,输入以下命令安装依赖: `pip install -r requirements.txt` `pip install -e .[metrics]` # 下载基座模型 本文使用的是`Meta-Llama-3.1-8B-Instruct`模型(一共30G) `Meta-Llama-3.1-8B-Instruct`是Meta公司(原名Facebook)推出的一款语言模型,旨在通过优化指令任务处理能力,提供更精准、更个性化的服务体验。 https://modelscope.cn/models/LLM-Research/Meta-Llama-3.1-8B-Instruct/files 在下载前,请先通过如下命令安装ModelScope `pip install modelscope` 下载完整模型库到指定文件夹 `modelscope download --model LLM-Research/Meta-Llama-3.1-8B-Instruct --local_dir 'D:\models'` 如果不指定,默认下载到: `C:\Users\Administrator\.cache\modelscope\hub\`,下载完以后也可以移动到其他目录 # 下载自定义数据文件 文件链接: https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama_factory/data.zip 解压上一步下载的自定义数据集data.zip文件。 把`train.json`和`eval.json`放在`LLaMA-Factory-main\data`目录下。 打开`LLaMA-Factory-main\data`目录下的`dataset_info.json`: 在前面加入两段: ``` "my_train": { "file_name": "train.json", "formatting": "sharegpt" }, "my_eval": { "file_name": "eval.json", "formatting": "sharegpt" }, ``` 如图:  # 启动LLaMA-Factory UI界面 在根目录打开cmd,运行如下命令: (最简单的办法是把下面的命令放到一个`run.bat`文件里面,双击启动) `python src/webui.py` 默认浏览器会自动打开: http://localhost:7860/ 先把语言修改为中文 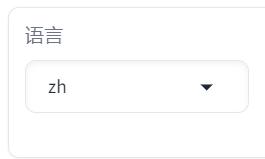 模型名称:`Llama-3.1-8B-Instruct` 模型默认路径(修改为你下载的模型路径):`C:\Users\Administrator\.cache\modelscope\hub\LLM-Research\Meta-Llama-3___1-8B-Instruct`  # 测试模型运行 <font color="red">注意,这一步非常消耗内存,而且响应非常慢</font> 点击“加载模型” 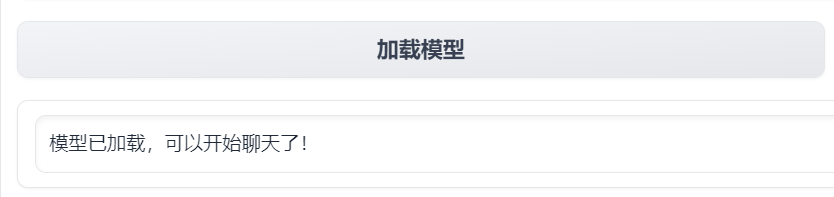 输入问题,点提交: 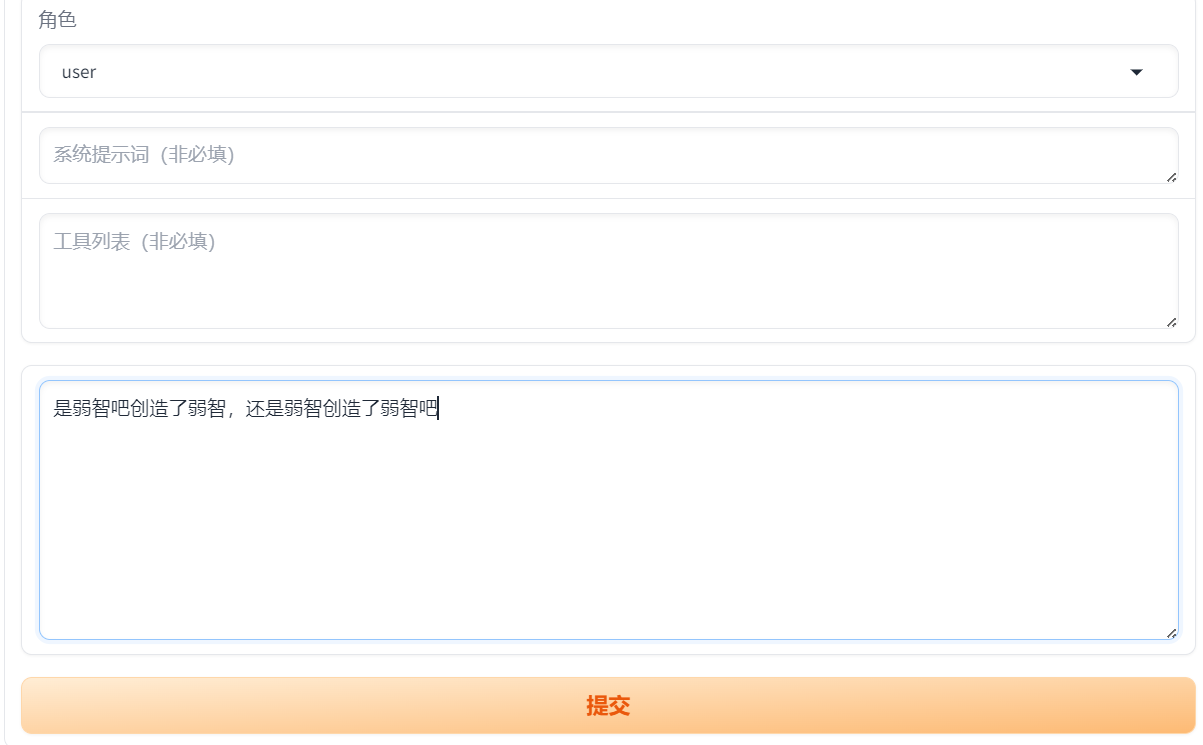 测试完以后“卸载模型”,释放内存  <font color="red">如果报错,回到启动webui的cmd窗口,里面会有具体错误信息,方便排查错误</font> 比如:  # 微调模型 点“Train”——加载数据集,可以预览数据集内容  点“开始”,开始训练,下面会显示训练日志。 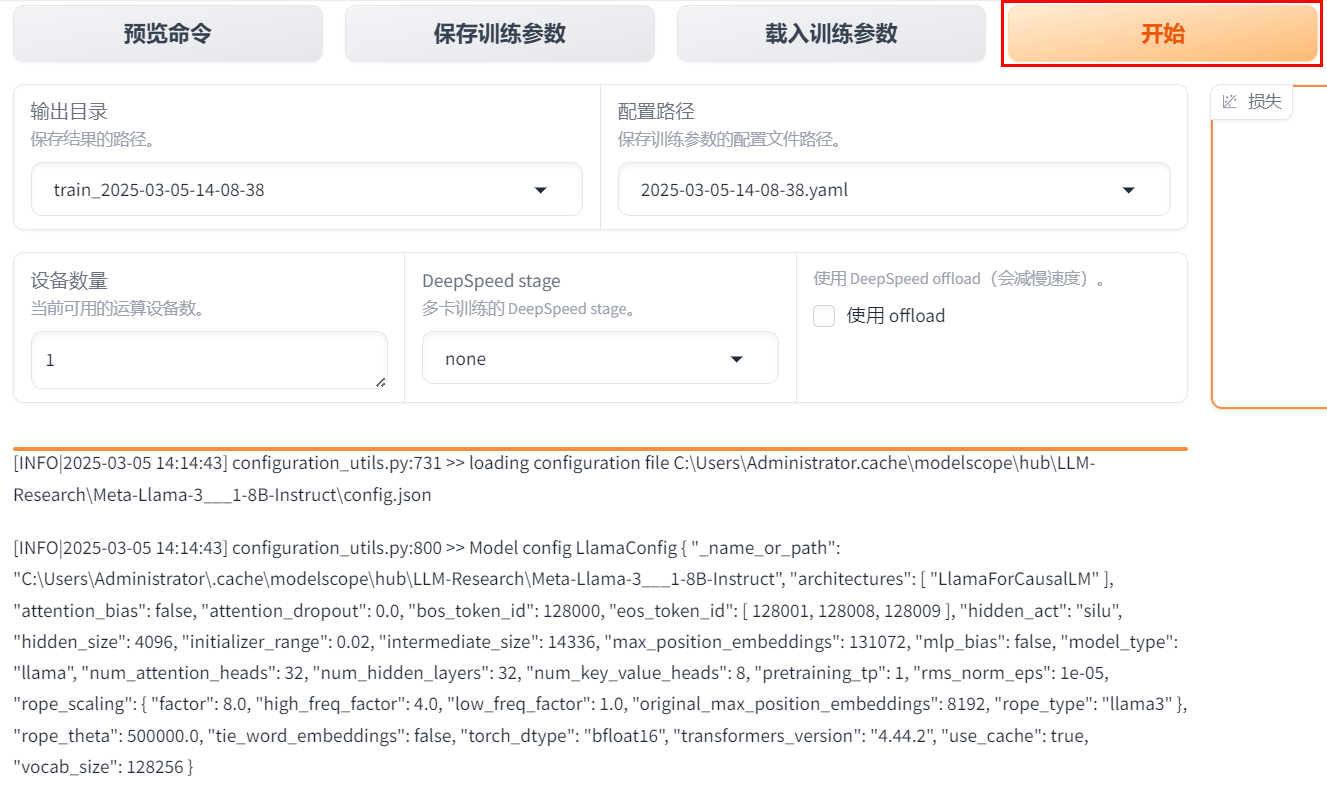 <font color="red">如果报错,回到启动webui的cmd窗口,里面会有具体错误信息,方便排查错误</font> 这里报了一个显存不足的错误:  Linux步骤参考: https://help.aliyun.com/zh/pai/use-cases/fine-tune-a-llama-3-model-with-llama-factory # 模型评估 模型微调完成后,单击页面顶部的刷新适配器,然后单击适配器路径,选择下拉列表中的train_llama3,在模型启动时即可加载微调结果。 在Evaluate&Predict页签中,数据集选择eval(验证集)评估模型,并将输出目录修改为eval_llama3,模型评估结果将会保存在该目录中。 单击开始,启动模型评估。 模型评估大约需要5分钟,评估完成后会在界面上显示验证集的分数。其中,ROUGE分数衡量了模型输出答案(predict)和验证集中的标准答案(label)的相似度,ROUGE分数越高代表模型学习得越好。 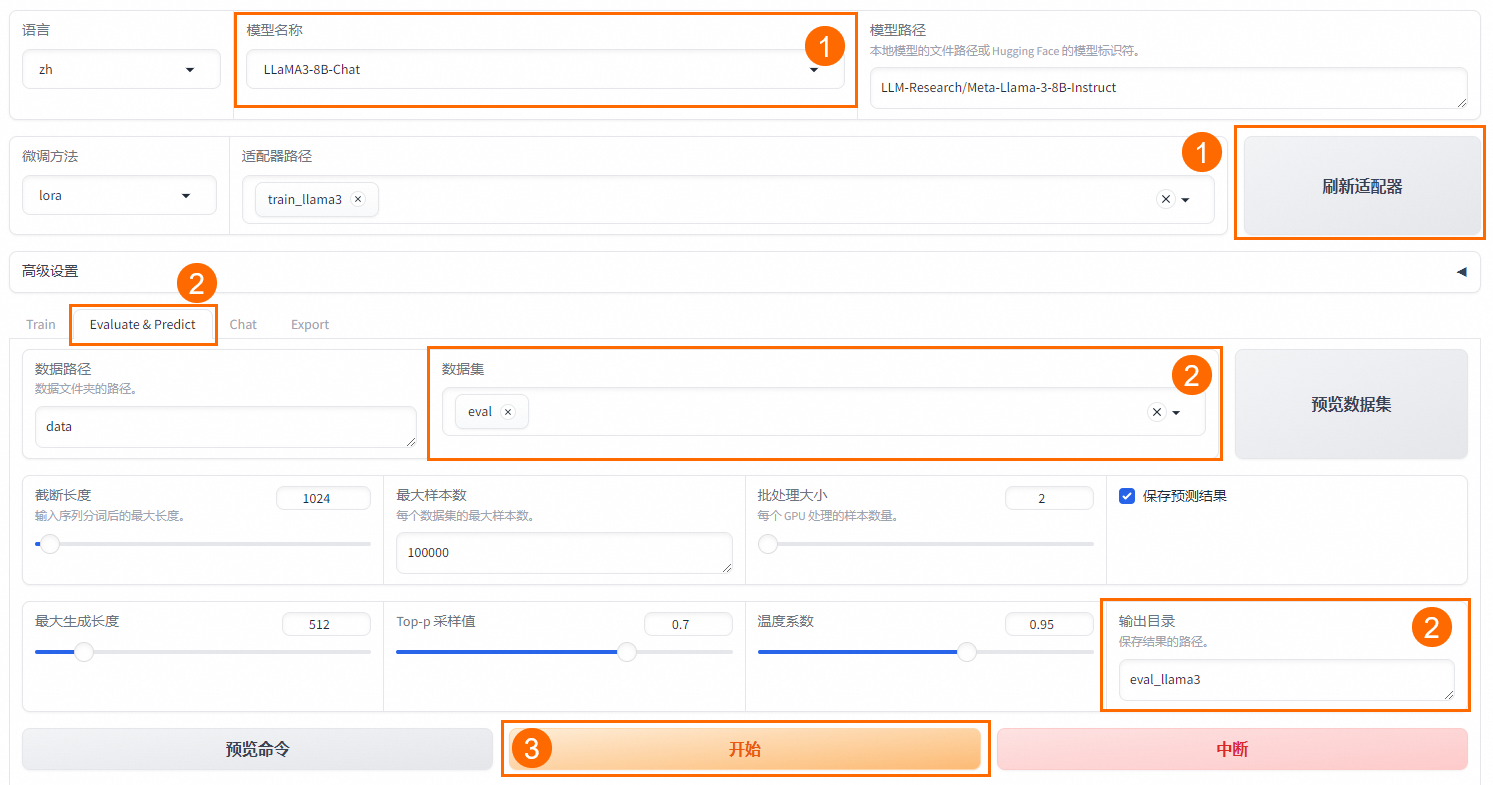 # 模型对话 在Chat页签中,确保适配器路径是train_llama3,单击加载模型,即可在Web UI中和微调模型进行对话。 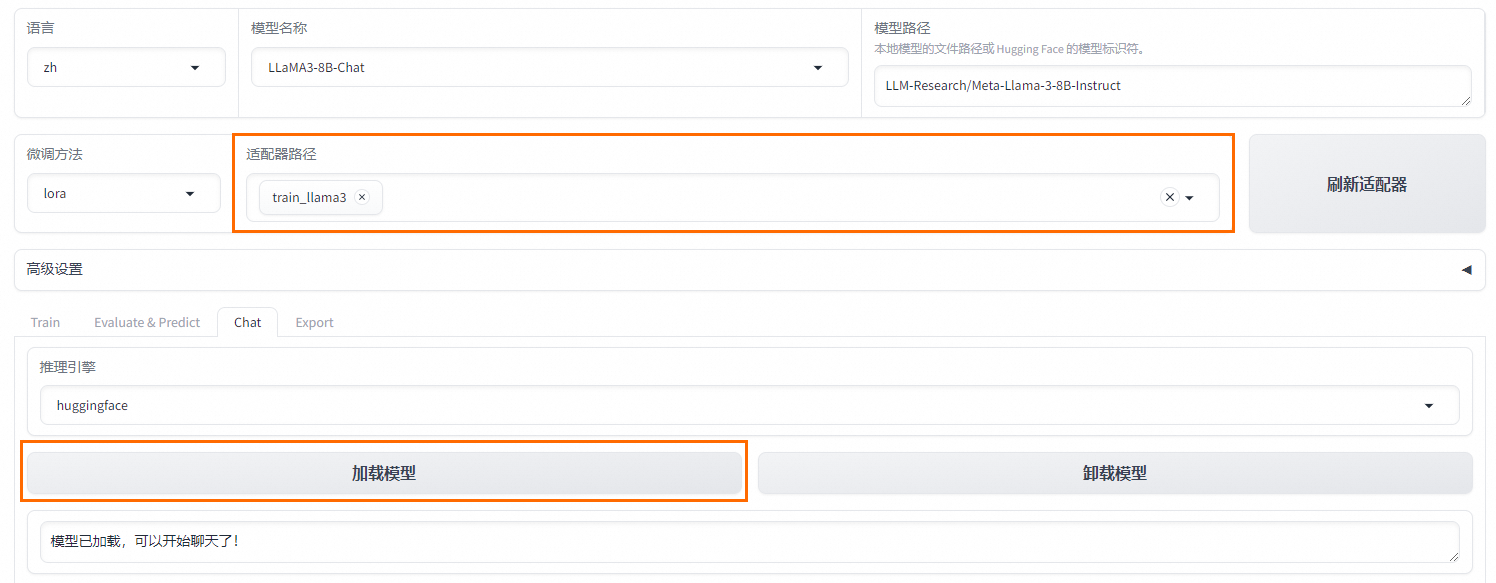 在页面底部的对话框输入想要和模型对话的内容,单击提交,即可发送消息。 发送后模型会逐字生成回答,从回答中可以发现模型学习到了数据集中的内容,能够恰当地模仿目标角色的语气进行对话。 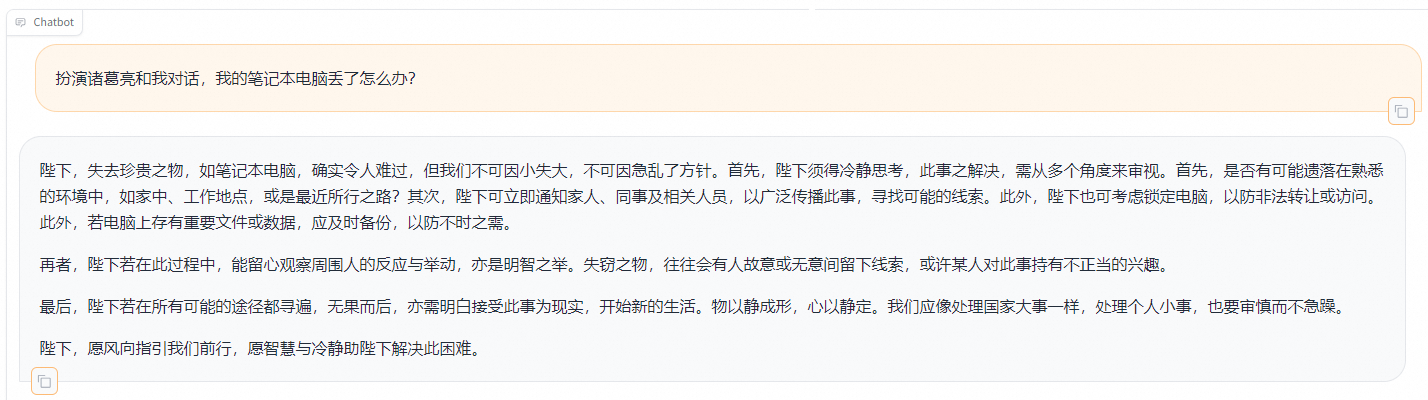 单击卸载模型,单击image取消适配器路径,然后单击加载模型,即可与微调前的原始模型聊天。 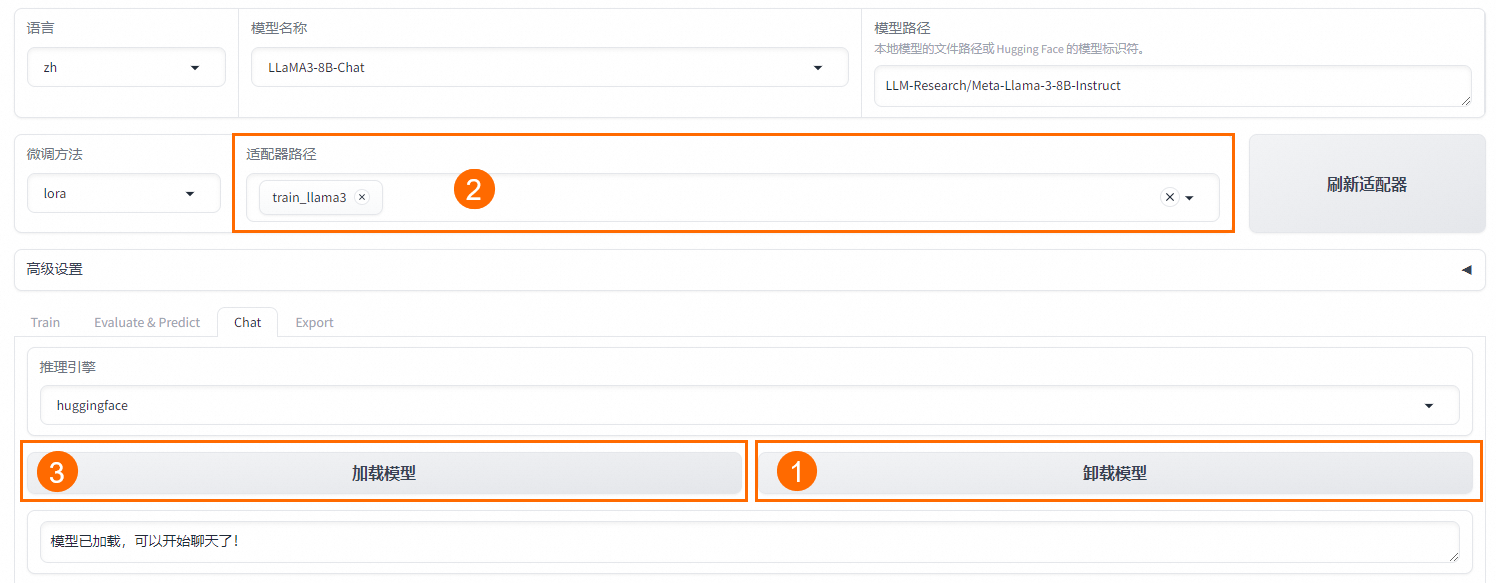 重新向模型发送相同的内容
无涯
2025年3月11日 16:46
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码