课程问题
【汇总】刻录BadUSB问题-社会工程学
【汇总】CVE-2022-22965-SpringRCE复现问题
Linux文件管理章节,排除exclude隐藏文件、查找不是以txt结尾的文件
Linux编辑模式如何恢复操作?
计算机网络-安装winPcap提示a newer version of WinPcap is already installed on this machine
MySQL表添加外键不生效
MySQL-phpMyAdmin登录失败
PHP代码在vscode不能执行
kali安装docker失败
CSRF漏洞学完了,怎么练习
kali apt安装软件提示:unable to locate package无法定位软件包
kali中beef-xss配置文件
msf安装viper炫彩蛇 docker-compose up -d 报错
【汇总】git信息泄露,githack利用不成功
【汇总】蚁剑antsword连接报错
Kioptrix Level 1靶机扫描不到IP
逆向课程吾爱破解工具包不能运行
【汇总】永恒之蓝漏洞/eternalblue/ms17-010复现不成功
跳板机发起攻击的问题
跳板机也会被追溯到吧,以为用访问日志和历史查看?
逆向课程,win10 64位的od 和IDA 在哪下?
vulnhub靶场prime1提权失败GLIBC问题
Linux git clone TCP connection reset by peer
ssrf与gopher与redis
CSRF课程靶场代码使用方法及问题解决
【汇总】SQL注入靶场sqli-labs连接/数据库初始化错误
sqli-labs靶场21关报错:mysqli_real_escape_string() expects parameter 1 to by mysqli, null given in
SQL注入floor报错注入原理
【汇总】SQL注入load_file不能读文件(secure_file_priv)
SQL注入 python盲注脚本出现了多余错误的字符
Kali——SQL注入的school靶场怎么搭建?
在使用sqlmap时,明明有注入点,却sqlmap跑不出来,会是什么原因?
CNNVD漏洞分类指南旧网址打不开
msf编码免杀执行报错:No .text section found in the template
zenmap(nmap windows版本)下载地址
【汇总】安装运行oneforall报错
PHP代码提示 expects parameter 1 to be mysqli_result bool given in
安装xsser报错,pkgProblemResolver
安装CodeTest报错
【汇总】DVWA靶场报错
PHP报错C:\php\ext\php_mysqli.dll (找不到指定的模块)
java-jar启动报错找不到或无法加载主类
【汇总】文件上传漏洞upload-labs无法复现汇总
SSH Key后门免密登录
localhost和127.0.0.1的关系
Apache添加mod security模块后无法启动
fastjson JdbcRowSetImpl利用链,为什么会自动执行恶意代码
反弹连接命令的含义
【汇总】Redis客户端不能连接到Redis服务端,卡住、超时或者拒绝连接
【汇总】反弹连接不成功(Redis未授权访问漏洞)
PAM依据什么找到服务对应的配置文件?
【汇总】文件上传漏洞upload-labs靶场无图片、无样式,打开关卡404
【汇总】Apache启动失败
【汇总】Fastjson复现失败总结和思路
免杀课程上的有溢出漏洞360版本在哪下
awvs web网站打不开
【汇总】vulhub靶场无法启动/连接
浏览器的cookie文件保存在哪里
log4j无法修改日志等级问题,只有error触发漏洞
Charles抓包问题
useradd 参数 -p 指定密码登录失败
tar -rf 往gz 压缩包里面追加文件
SQL注入中如users表名显示的字段名过多
Redis连接成功,但执行命令时报错(error) DENIED Redis is running in protected mode
青花瓷插件版本(charles证书导入burp suite)
SRC基础抓包 - proxifier抓小程序包报错
sqli-labs使用group_concat查询时报错:在没有GROUP BY的聚合查询中,SELECT 列表的表达式#3包含非聚合列'security.users.password;这与sql_mode=only_full _group_by 不兼容
nessus 报错 UnicodeDecodeError: 'gbk' codec can't decode byte 0xa2 in position 6588: illegal multibyte sequence
灯塔 timeout of 12000ms
SUID提权find -p问题
信息收集搭建代理IP|快代理的使用|搭建代理池
Webgoat Java源代码审计靶场问题汇总
【汇总】XSS课程sendmail收不到邮件
SUDO权限配置不成功
beef-xss启动失败
centos7替换yum源为阿里云报错正在连接 mirrors.xxx | 127.0.0.2|:80... 失败:拒绝连接。
交换互联互通基础-实验:三层网关通信 配置失败问题
cmd运行.py文件,会自动弹出pycharm
永恒之蓝漏洞run vnc没有反应
sed删除两个特定字符中间的内容
sqli-labs靶场报错group_concat does no exist
RuoYiv4.7.1启动报错java: 程序包io.swagger.annotations不存在
type-poc.php运行报错unexpected T_PAAMAYIM_NEKUDOTAYIM
typecho反序列化漏洞复现失败问题
安卓模拟器openssl转换burp证书报错
计算机网络-网络协议分析-威胁数据流实战Bravo-1.pcapng流量分析答案
打开了php.ini搜索magic_quotes_gpc = On找不到
获取windows保存的明文WiFi密码
反序列化工程serialize-vul只能查看.class不能查看.java源码
【汇总】codereg.py-ddddocr启动/识别问题
【汇总】shiro反序列化(包括内存马)复现问题
【汇总】pikachu-XSS后台-pkXss报错复现不成功
域控和域管理员有啥区别
csrf靶场bank登录出现404错误
PHP代码审计-bluecms靶场搭建
"echo PHP_EOL"查了是换行符的意思,但运行完却没有换行
思科路由器ip地址调试界面问题
【汇总】log4j漏洞复现不成功-原因和排查思路
MySQL约束不生效,插入数据不报错
sqlmap --os-shell失败 无写入权限
MYSQL80:ERROR 1045 (28000):解决方法
MYSQL:绕过权限验证存在的问题(mysqld --console --skip-grant-tables --shared-memory)
vmware workstation虚拟机列表没有“共享的虚拟机”
vulnhub-dc9-端口敲门以后无法连接
docker拉取镜像失败pulling fs layer
【汇总】Weblogic漏洞复现问题
xss-labs第14关、第15关问题
计算机网络课程-子网划分答案
sqlmap执行POST注入的两种方式(json注入)
逆向课程开发工具vs2008 vc6.0
sqli-labs靶场第21关cannot modify header information -headers错误
Cannot resolve plugin org.apache.maven.plugins:maven-resources-plugin:3.2.0
msi宏病毒,双击xlsm文件没有上线
【汇总】综合信息收集工具hbit运行相关问题
解决自建wooyun系统无法使用搜索功能
【汇总】easyocr运行报错
w8fuckcdn运行文件报错
执行net view报错6118
浏览器打开PHP文件显示源代码,没有运行代码
安装jwt-cracker报错idealTree:lib: sill idealTree buildDeps
burp插件HAE相关问题
Linux配置Java/JDK(Kali启动ysoserial.jar JRMPListener报错)
esedbexport工具的github地址已经失效
beef-xss报错in `require`: cannot load such file -- msgpack(LoadError)
【汇总】yum安装MySQL,mysql -uroot -p临时密码无法登录
灯塔ARL报错timeout of 12000ms exceeded
httpconn暴破dvwa第一个密码0000提示破解成功
【汇总】访问jsp文件报错:HTTP500内部服务器错误,无法编译为JSP类
【汇总】sqlmap运行报错
powershell脚本运行问题
【汇总】API漏洞-crapi靶场问题
Excel无法在未启用宏的工作簿中保存以下功能
CVE-2020-16848 SaltStack命令注入返回406 Not acceptable
【汇总】IDEA-Tomcat项目访问页面404,找不到localhost的网页
python2安装Crypto库报错
安装Typecho无法连接数据库Database Server Error
find -name加引号和不加引号的区别
【汇总】Docker逃逸问题-CVE-2019-5736-CVE漏洞复现
XXE漏洞,不能读取本地文件
vulnhub-breach1-war包报错
Apache Commons Collections复现问题
log4j工程unboundid依赖报错
【汇总】内存马AgentDemo工程报错
vulnhub-prime靶机显示异常
Shiro反序列化漏洞原理解释
内存马课程小马xiaoma.jsp上传文件失败
vulhub-log4j漏洞复现流程
【汇总】CVE-2021-31805-struts2 s2-062漏洞复现失败
安卓逆向手机选择
【汇总】WinRAR代码执行漏洞CVE-2023-38831
vulnhub靶机扫描不到ip地址
kill -9 杀不死ping baidu进程的问题
【汇总】CVE-2022-22947-Spring Cloud Gateway RCE(SpEL表达式)
XSS课程中存储型XSS靶场无法注册
XSS课程资料代码怎么使用
CVE-2018-12613-phpMyAdmin4.8.x文件包含漏洞
【汇总】CVE-2023-32233 NetFilter权限提升复现失败
XXE-payload详细解释
kali安装tcpxtract的问题
渗透实战-SRC漏洞挖掘第二期-章节2-课时5:SRC基础抓包-安装系统证书
breach1靶场反弹shell失败
pikachu靶场pkxss后台为什么不能记录中文
SQL报错注入获取到的数据不全
密码暴破-PHP工程yanzheng使用方法
demo_inxedu_open因酷教育工程启动问题
shiroattack工程依赖报错(shiro反序列化)
web js课程中对网站断点调试失败
Python武器库:暴力破解密码自动阻断代码问题
HTML课程中snippets插件失效
Java代码审计smbss部署问题汇总
Fastjson 1.2.24 RCE CVE-2017-18349 复现流程
Struts2 s2-061漏洞复现vulhub反弹连接
LMStudio下载了模型,但是找不到
Tomcat9.0.106下载链接404-Linux-系统资源状态管理-进程管理
【汇总】业务逻辑漏洞靶场 edu-logic-vul.jar使用问题
SQL注入过滤绕过fuzz字典
React-RCS RCE(CVE-2025-55182)漏洞复现
(虚拟机桥接)手机连接WiFi无法访问Kali下载MSF生成的apk文件
CTF-MISC-xctf-warmup压缩包隐写-明文攻击
vulhub漏洞复现-CMS_WordPress靶场安装问题
PHP反序列化CTF-Web_php_unserialize
本文档使用 MrDoc 发布
-
+
首页
nessus 报错 UnicodeDecodeError: 'gbk' codec can't decode byte 0xa2 in position 6588: illegal multibyte sequence
Nessus中文报表超大csv文件转换报错问题解决办法 # 解决办法 以前漏扫转换中文报表都很正常,这次漏扫转换直接报错,一看导出的 csv文件达到了20M, 报错如图: 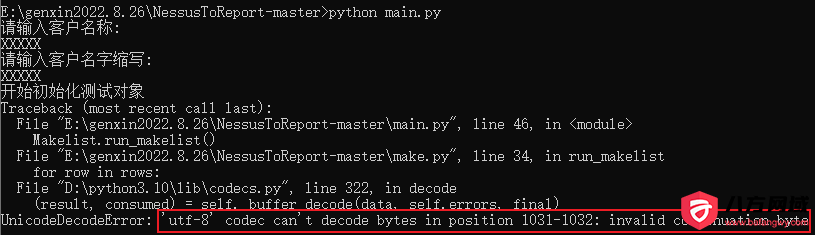 在网上查资料,说是超出了utf-8的编码范围, 随即修改make.py文件,utf-8改成gbk ``` with open(systems_file, "r", encoding="gbk") as f: ``` 仍然报错,可能是文本中出现的一些特殊符号超出了gbk的编码范围 > UnicodeDecodeError: 'gbk' codec can't decode byte 0xa2 in position 6588: illegal multibyte sequence 继续修改make.py文件, ``` with open(systems_file, "r", encoding="gb18030") as f: ``` 仍然报错,说明文中出现了连‘gb18030'也无法编码的字符,,可以使用‘ignore’属性忽略非法字符 > UnicodeDecodeError: 'gb18030' codec can't decode byte 0xa2 in position 6588: illegal multibyte sequence 继续修改make.py文件,添加errors='ignore' ``` with open(systems_file, "r", encoding="gb18030",errors='ignore') as f: ``` 如图:  最终完美运行  # 参考链接 http://bbs.bafangwy.com/forum.php?mod=viewthread&tid=479&extra=page%3D1
周浩
2024年2月26日 09:54
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
如果文档没有解决你的问题,建议把预期结果、命令、错误信息、截图等等发给**AI工具**提问,描述越详细越容易解决
Markdown文件
分享
链接
类型
密码
更新密码